학습목표
-
Set이 무엇인지
-
Queue가 무엇인지
-
왜 Set 을 써야하는지
-
왜 Queue를 써야하는지
-
Set은 어디에 쓰이는지
-
Queue는 어디에 쓰이는지
-
Set과 다른 자료구조와의 차이점은 무엇인지
-
Queue의 다른자료구조와의 차이점은 무엇인지
-
Set을 구현한 구현체들은 무엇이 있고, 각 차이점은 ?
-
Queue를 구현한 구현체들은 무엇이 있고, 각 차이점은?
Queue란 무엇인가??
큐는 FIFO의 용도로 사용한다. Fist In First Out의 약자로 먼저 들어온 애가 먼저 나가는 것을 말한다.
선입선출 구조이기 떄문에 서비스 대기열(버퍼)같은 경우에 사용하게 된다.
Queue를 왜? 어디에 써야하는가?
앞서 말한 예시와 같이 서비스 대기열(버퍼)를 구현할 때 사용될수 있으며, 순서를 보장해야할때 사용된다. 스트리밍(streaming), 너비 우선탐색(Breath Frist Search) 등에 소프트웨어 개발에 쓰이고 있다. 버퍼를 가지는 모든 데이터에서 이 큐를 활용한다.
Queue와 다른자료구조의 차이점
Queue의 특별한 차이점은 선입선출 구조를 구현했다는 것이다. 즉 후입선출을 구현한 Stack과는 정반대의 개념의 자료구조라 할수있다. 처음과 끝을 구분하기위해 front,rear라는 변수가 있고, 데이터가 저장이되면 rear부터 저장된다. 데이터를 출력할때는 front부터 출력된다.

https://velog.io/@misun9283/Queue
Queue의 종류를 알아보자
선형 큐 (Linear Queue)
기본적인 큐의 형태
막대모양으로 된 큐로, 크기가 제한되었고, 빈 공간을 사용하려면 모드 자료를 꺼내거나 자료를 한칸 씩 옮겨야 한다는 단점이 있다.
선형 큐의 문제점
일반적인 선형 큐는 rear의 마지막 index를 가르키면서 데이터의 삽입이 이루어진다. 문제는 rear의 배열의 마지막 인덱스를 가르키게 되면 앞에 남아있는 (삽입 중간에 Dequeue되어 비어있는 공간) 공간을 활용 할수 없게된다. 이 방식을 해결하기 위해서는 front를 고정시킨채, 뒤에 남은 데이터를 한칸식 당기는 수밖에 없다.
원형 큐(Circular Queue)
선형 큐의 문제점을 보완하고자 나왔다.
배열의 마지막 인데스에서 다음 인덱스로 넘어갈 떄 '(index+1) % 배열의 사이즈'를 이용해 Out Of Bounds Exception이 일어나지 않고, 인덱스 0으로 순환되는 구조를 가진다.
Queue를 구현한 클래스들
LinkedList : 앞서 List를 배울 떄 배웠던 자료구조다. List, Queue,Deque를 모두 구현하고 있는 클래스다. 이미 앞선 포스팅을 통해서 많이 알아보았으므로 생략한다.
PriorityQueue : 우선순위 큐 라고도 한다. 일반적인 Queue와는 동작하는 방식이 완전히 다르다.
PrioriyQueue란?
-
PriorityQueue란?
-
PriorityQueue는 어디에 쓰이는가?
-
PriorityQueue 특징과 구현원리
들어간 순서에 따라 출력되는 구조인 FIFO가 아닌, 일정한 규칙에 따라 우선순위를 정하고, 이 순위가 높은 데이터 순서대로 반환한다.
ProirityQueue를 왜?? 어디에 쓰일까?
우선순위에 따라 데이터를 출력,반환하므로 입력순서에 관계없이 특정 규칙에 따라 데이터를 처리해야할 때 쓰일수 있겠다. 스케줄러나 캐시교체알고리즘에 적용될수 있을것 같다.
PriorityQueue의 특징과 구현원리
PriorityQueue의 특징은 앞서 말했듯이, 우선순위에 따른 데이터의 출력이다.
이런 PriorityQueue를 구현하기 위해 배열,리스트,힙 자료구조를 사용할 수있는데, 일반적으로는 힙(heap)이라는 자료구조를 이용해서 구현한다.
배열이나 리스트를 사용할 경우 삽입,삭제과정에서 데이터를 한칸식 당기고 미는 연산이 필요하고, 리스트는 삽입,삭제 위치를 찾기위해 순차적인 접근은 하므로 성능저하가 일어난다.
그렇다면 힙(heap)이란 무엇일까??
Heap이란 무엇인가?
힙(heap)은 '최솟값 또는 최댓값을 빠르게 찾아내기 위해 완전이진트리 형태로 만들어진 자료구조'다. 여기서 중요한 키워드 3가지를 기억하자. 최솟값or최댓값, 빠르게, 완전이진트리
그럼 heap을 이해하기 위해서는 먼저 완전이진트리에 대해서 이해해야 한다.
완전이진트리(complete binary tree)란 마지막레벨을 제외한 모든 노드가 채워져있으며, 모든 노드(=사실상 마지막 레벨의 노드들)가 왼쪽부터 채워져있어야 한다.

https://st-lab.tistory.com/205https://st-lab.tistory.com/205
Heap은 어떻게 구현하나??
Heap은 완전이진트리이며, 최댓값 혹은 최솟값을 빠르게 구한다고 했다. 완전이진트리가 무엇인지는 알았다. 그럼 어떻게 최댓값이나 최솟값을 빠르게 구할수 있을까?
예를들어보자, 어떤 리스트에 값을 넣었다 빼려고 할때, 우선순위가 높은 것 부터 빼내려고 한다면 대개 정렬을 떠올린다. 쉽게 생각해 내림차순으로 우선순위가 높다면 매번 새원소가 들어오고 나갈때 마다 기존 원소들과 비교 정렬을 해야한다.
이렇게 되면 삽입,삭제 연산시 O(N)의 연산을 수행하게되고, 비효율적이 된다. 때문에 효율을 좀더 좋게 하고자 다음과 같은 조건을 붙였다.
부모노드는 항상 자식노드보다 우선순위가 높다.
즉, 모든 요소들을 고려해 우선순위를 결정할 필요없이, 부모노드는 자식노드보다 항상 우선순위가 앞선다는 조건만 만족시키며 완전이진트리 형태로 채워나가는 것이다.
즉, 루트노드는 항상 우선순위가 높은 노드라는 뜻이다. 이러한 원리를 이용, 최댓값과 최솟값을 빠르게 찾아낼수 있다는 장점 O(1)(루트노드만 반환하면된다.) 삽입삭제 연산시에도 부모노드가 자식노드보다 우선순위만 높으면 되기에, 결국 트리의 높이만큼 비교를 하면된다. O(Log N)
또한 위의 이미지에서도 볼수있듯이, 부모노드와의 우선순위만 비교하기 때문에, 같은 레벨에 있는 형제노드끼리는 비교하지 않는다. 이런 상태를 흔히 '반 정렬상태' , '느슨한 정렬 상태','약한 힙(weak heap)' 이라고 불린다.
왜 형제간의 우선순위는 고려하지 않을까? 아래의 구현부분을 보면서 이해해보자
Heap의 구현
트리구조를 구현할때 가장 표준적으로 사용되는 것은 '배열'이다. 연결리스트로도 구혀이 가능하지만, 특정 노드의 검색, 이동 과정이 배열보다 번거롭기 때문에 배열을 사용한다.
배열로 구현시 몇가지 특징과 장점이 있는데 아래그림을 보자

https://st-lab.tistory.com/205https://st-lab.tistory.com/205
특징
구현의 용이함을 위해 시작 인덱스(root)는 1부터 시작한다.
각 노드와 대응되는 배열의 인덱스는 '불변한다'
위의 특징으로 인해 다음과 같은 성질이 나타난다.
성질
왼쪽 자식 노드 인덱스 = 부모노드 인덱스×2
오른쪽 자식 노드 인덱스 = 부모노드 인덱스×2+1
부모노드 인덱스 = 자식노드 인덱스 / 2
예를들어 index3의 왼쪽 자식노드를 찾고 싶다면 3×2 = 6 으로, index 6이 왼쪽 자식노드이다.
반대로 index 5의 부모노드를 찾고 싶다면, 5/2 = 2(몫만 취한다.) 로 index 2가 부모노드이다.
삽입연산(add)
Heap의 삽입은 크게 두가지로 나뉜다.
사용자가 Comparator를 사용, 정렬방법을 Heap생성단계에서 넘겨받는 경우
클래스 내에 정렬 방식을 Comparable로 구현하거나, 기본정렬방식을 따르는 경우
기본적으로 Heap에 원소가 추가되는 과정을 아래의 이미지들을 통해 알아보자.
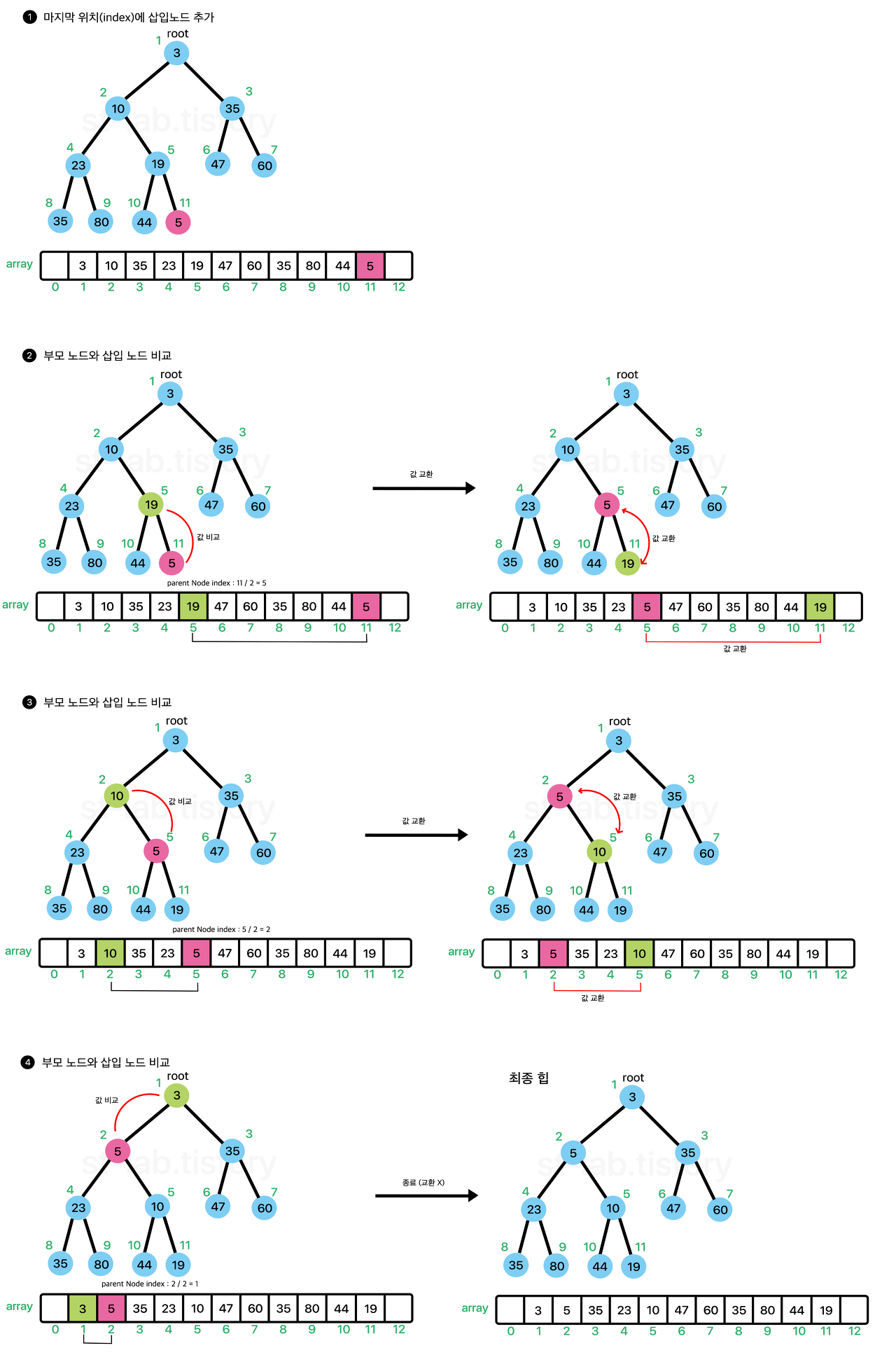
https://st-lab.tistory.com/205
즉, 배열의 마지막 부분에 원소를 넣고, 부모노드를 찾아가며 부모노드가 삽입노드 보다 작을 때까지 원소를 교환해 가며 올라간다. 위와 같은 과정을 올라가며 선별한다하여 sift-up(상향선별)이라고도 불린다. 즉 값을 추가할때는 size+1의 위치에 값을 추가후, 트리를 재배지하는 과정을 수행한다고 보면 된다. 시간복잡도는 O(Log N)이다.
삭제연산(remove)
그렇다면 삭제연산은 어떻게 될까? 간단한다. 삽입연산과 정반대로 행하면된다.
add의 경우엔 맨 마지막 노드에 추가하고 부모노드와 비교하며 자리르 찾아갔다. 이를 거꾸로 하면 루트노드를 삭제하고, 마지막에 위치한 노드를 루트의 위치로 가져와 재배치작업을 수행하면 된다.

https://st-lab.tistory.com/205
위 이미지와 같이 진행되며, 시간복잡도는 O(log N)이 나온다.
PriorityQueue의 특징
Java의 PriorityQueue클래스의 특징은 곧 Heap자료구조의 특징과도 같다. 대부분이 Heap자료구조를 이용하기 때문에, 삽입과 삭제에 O(Log N)의 시간복잡도를 가지며 항상 루트노드에 우선순위가 높은 노드가 위치하게 된다.
Deque란?
LinkedList는 List와 Queue그리고 Deque를 구현했다고 했다. 그럼 Deque는 무엇일까?
Deque란 Double Endend Queue의 약자이다.
선입선출구조로 데이터의 삽입 rear로, 데이터 출력은 front로만 가능했던 Queue와 달리, 양 끝에서 모두 출력과 입력이 가능하다.
Deque는 왜쓰는것일까?
Deque는 양 끝에서 모두 출력과 입력이 가능하다고 했다. 즉, FIFO와 LIFO가 가능한 자료구조이다. Vector를 상속받아 비효율적인 Stack대신에 Deque를 사용할수 있다.
알게 된 점
-
Set이 무엇인지
- Set은 Collection을 확장한 인터페이스로, 순서가 없으며 중복을 허용하지 않는 자료구조이다.
-
Queue가 무엇인지
- Queue는 LIFO를 구현한 Stack과는 반대로 FIFO를 구현한 자료구조이다. 즉 선입선출 구조를 구현한 자료구조이다.
-
왜 Set 을 써야하는지
- 순서가 없고 중복을 허용하지 않기 때문에, 이런 작업에 있어서는 Set을 쓰는것이 성능상 이롭다.
-
왜 Queue를 써야하는지
- Queue는 선입선출을 구현한 자료구조다. 즉, '순서'를 기억하며 데이터를 처리할 때 쓰인다.
-
Set은 어디에 쓰이는지
- 순서가 관계없고 데이터가 존재하는지 없는지 여부만 중요할때 쓰인다.
-
Queue는 어디에 쓰이는지
- Queue는 서비스대기열(버퍼)나 스트리밍, 너비우선탐색(BFS)등에 사용되고 있다.
-
Set의 다른 자료구조와의 차이점은 무엇인지
- 순서가 없고, 중복을 허용하지 않는다.
-
Queue의 다른자료구조와의 차이점은 무엇인지
Queue는 삽입될때 가장 뒤쪽으로, 나올때는 가장 앞에서 나온다.
front와 rear라는 변수로 처음과 끝을 구분하고 있다. (node의 head 와 tail 비슷한 느낌이다!)
-
Set을 구현한 구현체들은 무엇이 있고, 각 차이점은 ?
-
HashSet
HashSet은 내부적으로 HashMap을 호출, 구성관계를 가지고 있다.
순서가 없고, 정렬되어있지 않으며 HashMap을 사용하므로, 추가,삭제, contain등의 시간복잡도는 O(1)이다.
-
TreeSet
TreeSet은 이진탐색트리의 형태로 데이터를 저장 한다. 자바에서는 더 개선된 Red-BlackTree로 구현되어있다.
이진탐색트리란 이진탐색과 연결리스트(LinkedList)를 결합한 자료구조이다. 정렬된 탐색에서 큰 효율을 보이는 이진탐색과 추가와 삭제가 가능한 연결리스트를 결합했다.
이진탐색의 뜻은 찾고자하는 배열의 탐색범위가 단계를 거칠수록 반절로 줄어들기 때문에 붙여졌다.
이진탐색은 탐색하고자 하는 범위의 임의의 중간값 X를 선택, 찾고자 하는 값 Y와 비교하여 Y가 작으면 좌측으로, 크면 우측의 범위를 대상으로하여 동일한 탐색을 실행한다.(술게임 업다운에 적용됨)
이때 이진탐색의 시간복잡도는 O(logN)을 보장한다.
빅오표기법은 알고리즘의 효율성을 나타내는 지표로, 시간복잡도와 공간복잡도가 있다.
빅오표기법은 상수항을 무시하고, 가장 지배적인 항을 제외한 나머지 항은 무시한채 표기한다.
N개의 노드를 가진 일반적인 이진탐색트리는 모든연산에 대해 O(log₂N)을 보장한다. 하지만 편향적인 이진탐색트리에서는 노드의 갯수 N = 높이 H 가 되는 일도 발생할 수있다. 즉 최악의 경우 O(N)이 되어버린다.
최악의 경우 O(N)의 시간복잡도를 갖게 되는 이진탐색트리를 개선한 것이 Red-Black트리이다. Red-Black트리는 높이를 log₂N으로 한정할수있다. 즉 모든 연산에 대해서 시간복잡도가 O(log₂N)을 보장한다.
-
Red-Black 트리의 회전,삽입,삭제 연산에 대해서 꼭! 이해하자
-
LinkedHashSet
-
LinkedHashSet이란?
- 입력된 순서를 기억하고, 그 순서대로 출력한다. TreeSet처럼 정렬이 아닌, 입력순서대로 순서를 기억한다.
-
왜? 어디에 쓰이는가?
- 중복을 허용하지 않고, 입력된 순서를 기억해야 할때 쓰인다.
-
LinkedHashSet의 특징 과 구현원리
LinkedHashSet은 HashSet에 들어가는 노드들이 key와 value외에, next,prev 값을 가짐으로써, 나 이전과 이후의 순서를 기억하고 있는 자료구조이다.
forEach문코드를 보면 head 노드부터 next의 변수를 차례로 호출하는것을 볼수있다.
이외에는 HashSet과 같은 원리이다.
-
LinkedHashSet이 성능이 제일 안좋다고 했는데 왜 일까??
- 알수없음.... 책이 잘못나온걸까?... 인터넷에 검색해봐도 나오지 않음 일단 질문했음
-
-
-
Queue를 구현한 구현체들은 무엇이 있고, 각 차이점은?
LinkedList 와 PriorityQueue가 있으며, LinkedList는 List,Queue,Deque를 모두 구현한 클래스다.
PriorityQueue는 일반적인 Queue와 달리 각 데이터에 우선순위를 부여, FIFO가 아닌, 우선순위가 높은 값을 먼저 출력하는 형태이다.
-
PriorityQueue란?
-
Heap 자료구조
-
Heap이란 무엇인가?
- 완전이진트리란?
-
Heap은 어디에 쓰이나?
-
Heap의 특징과 구현원리 → 작동방식은 이해함. 구현코드로 명확히 이해하지 않음
-
-
-
PriorityQueue는 어디에 쓰이는가?
-
PriorityQueue 특징과 구현원리 → Heap의 특징과 비슷하다. 그러나 명확한 이해 X
Deque란?
Double Ended Queue의 약자로 양끝에서 모두 삽입과 삭제가 일어나는 자료구조
LIFO와 FIFO모두 구현이 가능하다.
LIFO가 가능함에 따라 Vector를 상속받은 Stack대신 ArrayDeque를 권장한다.
-
Deque는 어디에? 그리고 왜 쓰이나?
Reference
'프로그래밍 > Java' 카테고리의 다른 글
| 람다와 스트림의 사용법(1) (0) | 2021.06.10 |
|---|---|
| Thread(1) (0) | 2021.06.02 |
| 캐시 교체알고리즘 과 상황별 효율성 (0) | 2021.06.01 |
| Map (0) | 2021.05.31 |
| Set과 Queue -Reboot(3) (2) | 2021.05.31 |


